
Pentest Chronicles
Why you shouldn't roll your own cryptography - real-life case in 2023.

MATEUSZ LEWCZAK
August 28, 2023
In the world of IT, a common practice has emerged where cryptography is developed by a group of researchers possessing a strong mathematical background, while developers implement ready-made solutions and ensure that they are up-to-date and meet the best security practices.
Taking this into consideration and adding the fact that desktop application testing is often carried out by pentesters who may overlook issues related to encryption or hashing, while focusing on searching for known vulnerabilities, it should be expected that the unexpected can happen. As the following text will prove, a deeper understanding of this topic can yield surprising results, and ultimately lead to the theft of all users' desktop application accounts.
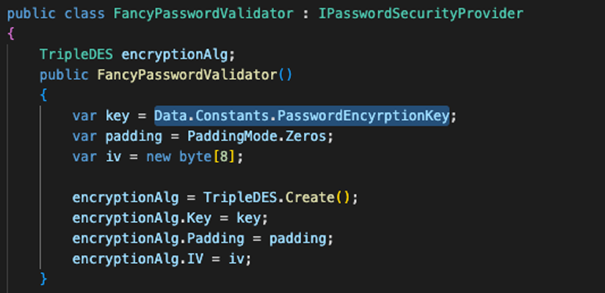
Recently, while testing a real desktop application, I came across a custom database password hashing algorithm based on the 3DES encryption algorithm. While at first glance this seems like madness, since the hash function should be, by definition, unidirectional with no possibility of decryption. In truth there are many hash algorithms that use symmetric encryption, for example:
The algorithm had little in common with the cited algorithms. So, I will show you a technique to attack such algorithms that have been applied in a real application. First, it is worth starting from the fact that the application was written in .NET, in addition, the code was not obfuscated, due to the fact I used ILSpy tool which allows to decompile source code. The application and the database are connected directly to each other (2-tier architecture) and the client-side authentication was implemented, which should not be possible because the user can influence its process. After a thorough search of the application code, I found a C# class that implemented hash calculating.
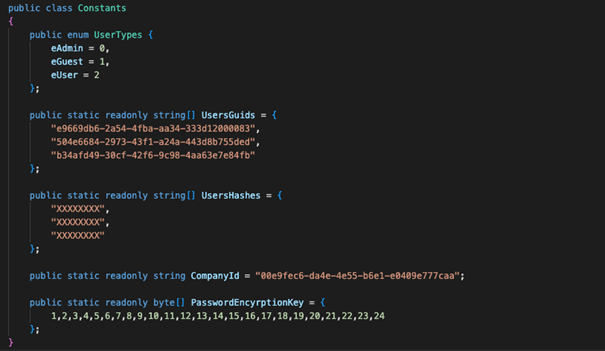
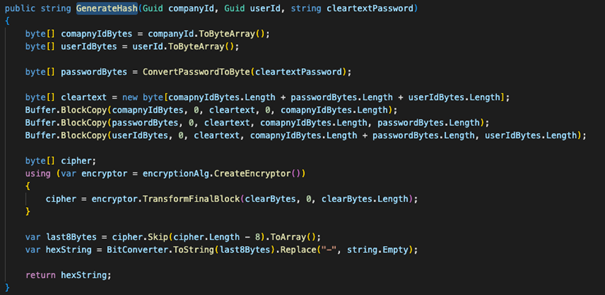
The value of the companyID, userID and hash can be found in the database. The length of each GUID is equal to 16 bytes, and the password is encoded in Unicode, so each character occupies exactly 2 bytes of memory. For example, this is what the plaintext would look like for each field:

The ciphertext will be presented in the following form:
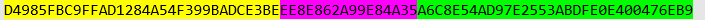
The hash, will contain the last 16 characters (8 bytes):
ABDFE0E400476EB9
TripleDES using CBC divides the plaintext into blocks of 8 bytes, which it first encodes with an XOR operation using an initialization vector and only then encrypts. For the first block, the initialization vector is predetermined by the programmer (in this case 0x00000000000000000000), while each subsequent initialization vector is already encrypted as the product of the previous block:

In the case of decryption, the order is reversed - decryption starts with the last block, then is decoded with an XOR operation using the encrypted previous block:

You are probably wondering how you can access userId and comapnyId. In the user table, the database contained all the necessary data to construct the plaintext. The database itself could be accessed through the application, which had database credentials in the source code. Each user had assigned an identifier (userId), a company identifier (companyId) and a password hash, which is our target.
Password restoration
In order to successfully recover the password, the ciphertext must first be recreated, by the hash you already have. In the Cipher Block Chaining algorithm, we use a key and an initialization vector to encrypt each block. The key remains constant for each block, but the initialization vector is simply the value of the previous encrypted block, hence the word 'Chaining' in the name of the algorithm.
Data encryption is done from the first block to the last, while decryption is done from the last block to the first. The method described here is based on guessing the initialization vector byte per byte in such a way that when the block is decrypted, we get the expected result, in this case the userId.
Taking following steps allows a bad actor to recover any password from the database. Hash, userId and companyId used in this example were found in the database as I mentioned in previous section.
1. The attacker has all the necessary data. Found hash has the following form:

2. He or she also knows that userId is:

3. Now attacker’s task is to find such an initialization vector that the hash after decryption yields:

4. Attacker takes the simplest initialization vector 0x000000000000000000000000 and starts enumerating byte by byte from 0x000000000000000000000000 until our hit, which is 0x0000000000000053, after decryption gives last byte of userID so we know that’s the correct value:

5. Attacker then repeats this operation for the next bytes until a vector in the form 0xA6C8E54AD97E2553 is obtained, which is the penultimate block of the ciphertext. At this stage, the recovered ciphertext is:

6. Then all steps should be repeated for the discovered block and the next 8 userId bytes.
7. After these steps, the attacker already has the last three blocks of the ciphertext, as I mentioned before, the last two blocks are the userId, while the third is the password:

8. Now add comapnyId to the beginning of the ciphertext:

9. The final step is to decrypt the message and recover the password:

Password collision
A password collision is a situation where two different passwords produce the same hash. For an attacker, this situation is convenient because it does not require them to crack the password, which requires time, hardware, and adequate preparation. The advantage of an attack through collision is time and efficiency. The attacker can thus generate another password in a short period of time, which gives the same hash, and use it to log into the user's account.
As in the first case, it should be based on finding successive blocks of ciphertext, but with the assumption that the real password will not be found. For ease of calculation, it is worth assuming that the length of the password we want is a multiple of four. This way, the password will occupy the entire block of the ciphertext.
In this attack, I take advantage of the fact that the C# language encodes the string in Unicode. As a result, the attacker only needs to retrieve three blocks of the ciphertext and then add the companyID to the beginning. In this example, the following data will be used:
• companyID - a5b440d3-ec2c-4da3-b85f-a6bd10033ac8 (highlighted in yellow),
• userID - e945ff16-c29d-4eaa-a680-ece95af45cb6 (highlighted in green),
• password - hash-test-very-secure-password1! (highlighted in purple).
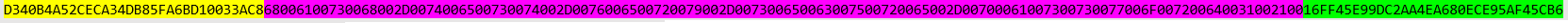
The ciphertext will be in the following form:

The hash, will be the last 16 characters (8 bytes):

Having all the data beyond the original ciphertext, the attacker can use the method outlined in the first case and obtain one potential ciphertext:

After decrypting this message, we get the following content:

As it turns out, the hash for the password 4dc1f98e556996fb (in hexadecimal representation) is the same as for the password:

Now all that remains is to transfer this value into actual Unicode characters, for which you can use https://unicode-table.com/pl/. Note that in the hexadecimal representation, the byte order is reversed and so, for example, a5e6 should be written as e6a5. Due to the huge number of languages and alphabets, an appropriate representation of each is required. For this reason, the Unicode array was created, which uses two bytes (65536 possible characters) and so, for example, the capital letter A is 0041, while B is 0042, and in the other direction 4141 is 䅁:

But let us now assume that we cannot create a valid string after all. For this reason, the password length must be increased to eight characters and a new ciphertext generated:

The algorithm assumes that, when counting each subsequent block, the value of the previous one is 0x41414141414141414141 to be able to get the characters in the available range, so after decryption we get the following proposal:

This operation should be repeated until you have characters that can be copied. If, after increasing the length of the password to eight characters, you do not get characters in the given range, you can change the assumed string 0x41414141414141414141 to 0x42424242424242424242 or another. It is also potentially possible to continue increasing the length.
For the given presumed string and previous hash, there is also a password of 12 characters, which gives an identical hash:

Now that I have the generated string, we can use it to log into the victim's account. After entering the password in the login form field, the application will calculate the password hash using the same algorithm as for authentication purposes. It will then compare it with the hash stored in the database. Due to a vulnerability in the algorithm, these hashes will be considered identical even though passwords are different. Consequently, the attacker will gain access to the victim's account.
Next Pentest Chronicles

When Usernames Become Passwords: A Real-World Case Study of Weak Password Practices
Michał WNękowicz
9 June 2023
In today's world, ensuring the security of our accounts is more crucial than ever. Just as keys protect the doors to our homes, passwords serve as the first line of defense for our data and assets. It's easy to assume that technical individuals, such as developers and IT professionals, always use strong, unique passwords to keep ...

SOCMINT – or rather OSINT of social media
Tomasz Turba
October 15 2022
SOCMINT is the process of gathering and analyzing the information collected from various social networks, channels and communication groups in order to track down an object, gather as much partial data as possible, and potentially to understand its operation. All this in order to analyze the collected information and to achieve that goal by making …

PyScript – or rather Python in your browser + what can be done with it?
michał bentkowski
10 september 2022
PyScript – or rather Python in your browser + what can be done with it? A few days ago, the Anaconda project announced the PyScript framework, which allows Python code to be executed directly in the browser. Additionally, it also covers its integration with HTML and JS code. An execution of the Python code in …
