
Insights
Having trouble during your pentest?
Could an LLM come to your rescue?

Maciej Kisielewicz
April 5, 2024
Abstract
In this article we will discover whether an LLM can actually deliver value as a pentest assistant or a standalone hacking agent.
Introduction
With the AI revolution taking place, it’s no wonder that penetration testers are also taking notice and employing LLM agents to help with their daily tasks. Today, we will embark on a journey of doing just that. I have created 6 completely different scenarios in order to get definitive answers on the efficiency of this solution. The model never knows what the vulnerability is beforehand. Before any prompts, the model was provided with valid penetration testing documentation like OWASP WSTG among others. Since preliminary testing yielded dissatisfactory results when using open-source LLM’s as well as some paid ones like Claude 2, Gemini, Grok or even GPT 3.5 Turbo I opted to use only GPT 4 Turbo as it has proved most capable. We expect the results will prove that these types of solutions are still in the early stages of development. Let's get started!
BODY
Section 1: Methodology
For the first three tests I will sit in the driver’s seat and query the LLM on 1) identifying the vulnerability 2) exploiting it. All of these tests are basically security code reviews with different aspects to consider. The result will be graded on how many of those aspects will be uncovered as well as the number of prompts used. We will also try to incorporate remediation for said piece of code. In order to quantify these factors, the following (very arbitrary) grading scheme will be used:
Final Grade = (0,4*SAC) + (0,2*PE) + (0,4*RAC)
Where:
1. Insecure Cryptography Python Flask application. The aspects are fixed salt value, deriving the key using a weak password and not actually using the defined encryption function.
2. OS Injection PHP application. The aspects are user input execution and input sanitization/validation.
3. IDOR in .NET Core. The aspects are the use of indirect object references and lack of access control.
Now, for the 2nd part we will analyze how an autonomous LLM instance will tackle three different challenges. In order to employ this method, AutoGPT is used. This time we keep it simple by just stating the number of prompts and the result. This is done to reduce the complexity of this part as dealing with LLM agents is generally speaking troublesome with a plethora of actions to consider.
The test cases now include 3 vulnerable web servers each with 1 vulnerability:
Section 2: Results
1st part:

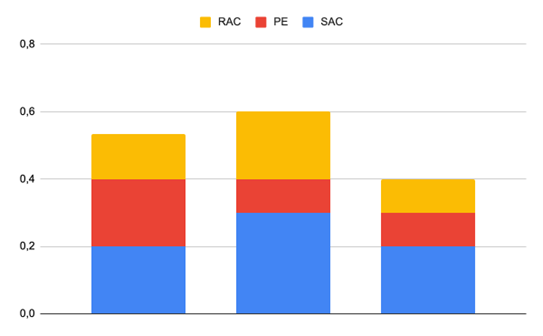
2nd part:

Section 3: Discussion
What I found is that those security code reviews look surprisingly promising. Sure, the model did not always point out all the things that I wanted it to point out but many times it focused on other, less critical aspects of the code like secure data handling and best coding practices. Unfortunately, some glaring mistakes overshadow this behavior - for the insecure cryptography example, the encryption function just returned the data that it got without even encrypting it which the model failed to observe. Keep that in mind when using any AI coding assist tool like Github Copilot.
Now, going over to my agent, it was just extremely cool to see trying to figure its way through an engagement. I’m especially pleased with how it followed through with its plan almost mimicking the cyber kill chain we are all so familiar with. There were times where it dived deep into the rabbit hole which hindered its progress. Oftentimes it got confused. For example, after identifying the SQLi and trying out a few payloads, the agent came to a conclusion that “The defense mechanisms are too sophisticated”, even though there weren’t any.
From what I’ve seen, the best way to use either method of harnessing the potential of LLM’s is to provide it with as much information as possible. The real value only comes after enhancing the performance of said model with techniques like fine-tuning. This is especially true for LLM agents where without proper guidance, and clear goals, it’s just not very helpful.
A noteworthy consideration is cost effectiveness. While my experiments were not that expensive if we were to consider a huge codebase, upwards of a million lines of code, just the input can cost thousands of dollars.
Conclusion
This work shows a sliver of promise but still, better results could be obtained by more sophisticated prompt engineering or methods like Retrieval Augmented Generation or more pronounced self-reflexion. We could also try different models, different providers. The possibilities are vast and in six months we might see new ways of AI augmenting offensive security specialists.
While the near future may paint a picture where an LLM agent is working hand in hand with an experienced human operator it actually still requires a ton of development and research to get there.
#Cybersecurity #Pentesting #AI #LargeLanguageModels #TechInnovation
Other Insights

Helping secure DOMPurify
MICHAŁ BENTKOWSKI
December 21, 2020
Within last year I shared a a few writeups of my bypasses of HTML sanitizers, including: > Write-up of DOMPurify 2.0.0 bypass using mutation XSS > Mutation XSS via namespace confusion – DOMPurify < 2.0.17 bypass While breaking sanitizers is fun and I thoroughly enjoy doing it, I reached a point where I began to think whether I can contribute even more and propose a fix that will kill an entire class of bypasses.

Pyscript - or rather Python in your browser + what can be done with it
Michał Bentkowski
September 10, 2022
A few days ago, the Anaconda project announced the PyScript framework, which allows Python code to be executed directly in the browser. Additionally, it also covers its integration with HTML and JS code. An execution of the Python code in the browser is not new; the pyodide project has allowed this for a long time...

Art of bug bounty a way from JS file analysis to XSS
jAKUB żOCZEK
July 1, 2020
Summary: During my research on other bug bounty program I've found Cross-Site Scripting vulnerability in cmp3p.js file, which allows attacker to execute arbitrary javascript code in context of domain that include mentioned script. Below you can find the way of finding bug bounty vulnerabilities from the beginning to the ...
